10. Data extract and file layout specification¶
This section identifies the layout and format of NOCC data files to be prepared and submitted by States and Territories to the Australian Government Department of Health.
10.1. Overview of data model for NOCC extract¶
10.1.1. The basic design of the extract consists of a set of data records for each Collection Occasion: the record of the Collection Occasion itself, together with the relevant associated records standardised measures and associated data items collected in respect of that Collection Occasion. Depending on the Episode Service Setting, Age Group and Collection Occasion, zero or one each of HoNOS, LSP, RUG-ADL, HoNOSCA, CGAS, FIHS, consumer self-rated measure and other individual data items (Diagnosis - Principal and Additional, Phase of Care, Mental Health Legal Status) may be recorded.
10.1.2. In addition, each Collection Occasion ‘belongs’ to an Episode of Mental Health Care, which in turn ‘belongs’ to Person (the consumer), who in turn is linked to a Service Unit (the principal or responsible provider of services), which is linked to a Hospital or Service Cluster, which is linked to a Mental Health Service Organisation, which is linked to a Region within the State/Territory.
10.1.3. The structure of data to be reported is represented in the data model shown in Fig. 10.1. Several features of the model should be noted.
10.1.3.1 Details of the Service Units reporting NOCC data are incorporated as part of the data extract, allowing linkage to related datasets provided by States and Territories (in particular, the NMDS – Mental Health Establishments).
10.1.3.2 Neither the concept of an Episode of Mental Health Care nor the concept of a Period of Care is represented as entities in the model. Information regarding either entity may be derived for statistical purposes from sequential instances of Collection Occasions.
10.1.3.3 Similarly, the concept of Person is not represented as an entity but is implicit, embedded within the Collection Occasion Details record. Information regarding persons who are the subject of the NOCC data can derived directly from information contained in Collection Occasion records.
10.1.3.4 The model separates the record for each individual standardised measure from the Collection Occasion, even though the measures have a one-to-one relationship with it. This enables additional measures to be more easily added as the need arises. It also makes the process of accommodating the different consumer self-report instruments that will be used by States and Territories less complex for all parties.
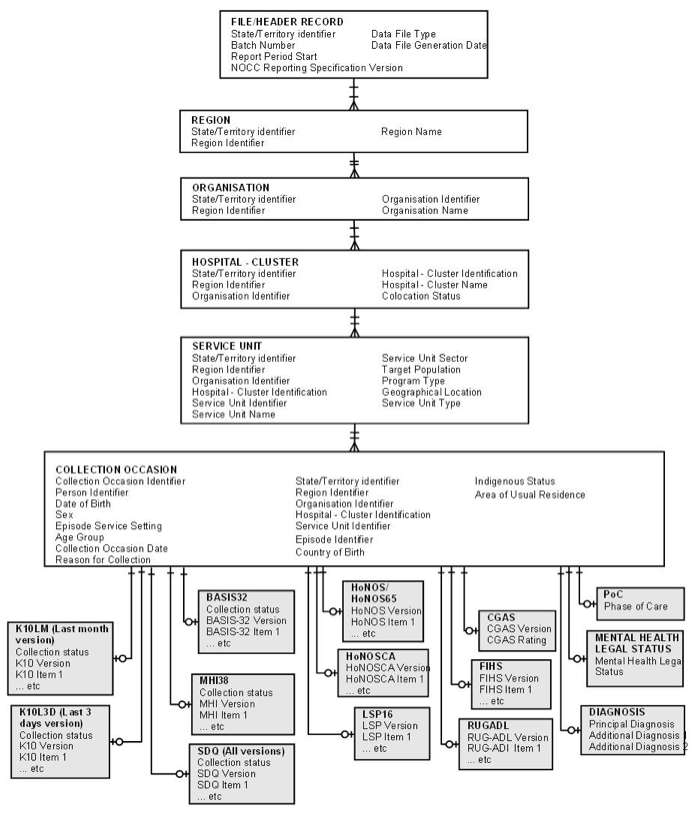
Fig. 10.1 Data model underlying the NOCC data extract
10.2. File type and naming convention¶
10.2.1. Data submitted to the Australian Government should be formatted as a Fixed Format data file, with each record in the file being terminated with Carriage Return (CR) and Line Feed (LF) characters.
10.2.2. The data file will have the naming convention of NOCCSSSYYYYNNNNN.DAT where:
- NOCC denotes “National Outcomes and Casemix Collection”.
- SSS is the abbreviation for the State or Territory name; using the following convention –
- for New South Wales use ‘NSW’,
- for Victoria use ‘VIC’,
- for Queensland use ‘QLD’,
- for Western Australia use ‘WAU’,
- for South Australia use ‘SAU’,
- for Tasmania use ‘TAS’,
- for the Australian Capital Territory use ‘ACT’,
- and for the Northern Territory use ‘NTE’;
- YYYY indicates the reporting year covered in the file, using the convention where financial years are abbreviated by referring to the last calendar year of the pair (e.g., the 2006–2007 financial year is identified as 2007); and
- NNNNN represents an incremental batch number (leading zeros present).
Note that successive quarterly files and any resubmitted files must have a batch number greater than all preceding files for that year.
For example, suppose that the Australian Capital Territory submitted quarterly data files in respect of the 2007–2008 financial year, then submitted a final submission for that year. Their first NOCC data file would be named “NOCCACT2008000001.DAT”, whilst the second would be named “NOCCACT200800002.DAT”, and so on. If no resubmissions were made the final submission for that year would be named “NOCCACT200800004.DAT”. If that file then had to be resubmitted for some reason, then it would be named “NOCCACT200600005.DAT”. Their first submission for the 2008–2009 financial year would then be named “NOCCACT200900001.DAT”.
10.3. Reporting period and delivery date¶
10.3.1. Files are to be prepared on an annual basis and sent to the Department of Health by 31 December each year, or closest working day).
10.3.2. Each annual file will include data for the immediately preceding financial year, e.g., December 2013 file should include data for the 2012-13 financial year.
10.4. File structure¶
10.4.1. The extract format consists of a set of hierarchically ordered Data Records, of which there are 19 types:
- Region details records
- Organisation details records
- Hospital or Service Cluster details records
- Service Unit details records
- Collection Occasion details records
- Diagnosis records
- Phase of Care records
- Legal Status records
- HoNOS or HoNOS65+ measure records
- LSP–16 measure records
- RUG–ADL measure records
- HoNOSCA measure records
- CGAS measure records
- FIHS measure records
- MHI–38 (consumer self–rated) measure records
- BASIS–32 (consumer self–rated) measure records
- K10+ Last Month records
- K10+ Last 3 Days records
- SDQ (all versions of both consumer and parent–rated) measure records
10.4.2. In each extract file for any given period, the Data records must be preceded by a single File Header Record having the structure outlined below under File header record.
10.4.3. All records presented in the extract file must be grouped in the following order: Header Record, Region details records, Organisation details records, Hospital – Cluster details records, Service unit details records, Collection Occasion details records, Diagnosis details records, Phase of Care details records, Mental Health Legal Status details records, HoNOS or HoNOS65+ measure records, LSP–16 measure records, RUG–ADL measure records, HoNOSCA measure records, CGAS measure records, FIHS measure records, MHI–38 measure records, BASIS–32 measure records, K10+ Last 3 Days measure records, K10+ Last Month measure records, and SDQ measure records.
10.4.4. The content and order of fields in a record must be the same as the order they are specified in the Record Layouts specified in the tables presented in Appendix A. Field values should be formatted as specified in the Record Layouts.
10.4.5. The first field in each record must be Record Type. Valid values are shown below.
| Record Type | Description |
|---|---|
| HR | File Header Record |
| REG | Region details |
| ORG | Organisation details |
| HOSPCLUS | Hospital – Cluster details |
| SERV | Service Unit details |
| COD | Collection Occasion Details |
| DIAG | Diagnosis |
| POC | Phase of Care |
| MHLS | Mental Health Legal Status |
| HONOS | HoNOS or HoNOS65+ |
| LSP16 | LSP–16 |
| RUGADL | RUG–ADL |
| HONOSCA | HoNOSCA |
| CGAS | CGAS |
| FIHS | FIHS |
| MHI38 | MHI (Consumer Self–Rated Measure) |
| BASIS32 | BASIS-32 (Consumer Self–Rated Measure) |
| K10L3D | K10+ (Last 3 Days Version) |
| K10LM | K10+ (Last Month Version) |
| SDQ | SDQ (all versions) |
10.5. Data integrity¶
10.5.1. Values in Date [Date] fields must be recorded in compliance with the standard format used across the National Health Data Dictionary, specifically; dates must be of fixed 8 column width in the format DDMMYYYY, with leading zeros used when necessary to pad out a value. For instance, 13th March 2007 would appear as 13032007.
10.5.2. Values in Numeric [Num] fields must be zero-filled and right-justified. These should consist only of the numerals 0-9 and the decimal (” . “) point if applicable.
Note: Fields defined as ‘Numeric’ are those that have numeric properties – that is, the values, for example, can be added or subtracted in a manner that is valid. Where a field uses numeric characters that do not have these properties (e.g. the use of numbers for Patient Identifier), the field is defined as ‘Character’.
10.5.3. Values in Character [Char] fields must be left justified and space-filled. These should consist of any of the printable ASCII character set (i.e. excluding control codes such as newline, bell and linefeed).
10.6. File header record¶
10.6.1. The first record of the extract file must be a File Header Record (Record type = ‘HR’), and it must be the only such record in the file.
10.6.2. The File Header Record is a quality control mechanism, which uniquely identifies each file that is sent to the Australian Government. (i.e., who sent the file, what date the file was sent, how many records are in the file, etc). The information contained in the header fields will be checked against the actual details of the file to ensure that the file received has not been corrupted.
10.6.3. The layout of the File Header Record is shown in Table 10.2.
| Data Element (Field Name) | Type [Length] | Start | METeOR Identifier | Notes / Values | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Record Type (RecType) | Char[8] | 1 | — | Value = HR | ||||||||||||||||
| State/Territory Identifier (State) [1] | Char[1] | 9 | 720081 |
|
||||||||||||||||
| Batch Number (BatchNo) | Char[9] | 10 | — | YYYYNNNNN | ||||||||||||||||
| Report Period Start Date (RepStart) | Date[8] | 19 | — | The date of the start of the period to which the data included in the current file refers. | ||||||||||||||||
| Report Period End Date (RepEnd) | Date[8] | 27 | — | The date of the finish of the period to which the data included in the current file refers. | ||||||||||||||||
| Data File Generation Date (GenDt) | Date[8] | 35 | — | The date on which the current file was created. | ||||||||||||||||
| Data File Type (FileType) | Char[4] | 43 | — | Value = NOCC | ||||||||||||||||
| NOCC Reporting Specification Version (SpecVer) | Char[5] | 47 | — | Value = 02.03 |
Record length = 51
Notes
| [1] | METeOR includes code 9, but that is not applicable to the NOCC |
10.7. Detailed record layouts¶
10.7.1 Detailed specifications on the extract format for all NOCC records are provided in Appendix A.
10.8. Data dictionary¶
10.8.1 Detailed definitions and data element domains or all components of the NOCC dataset are provided in Appendix B.
10.9. Data submission and validation requirements¶
10.9.1 Submission requirements and an overview of the requirements for data validation available at https://www.amhocn.org/submission-and-validation-process/mds-validator