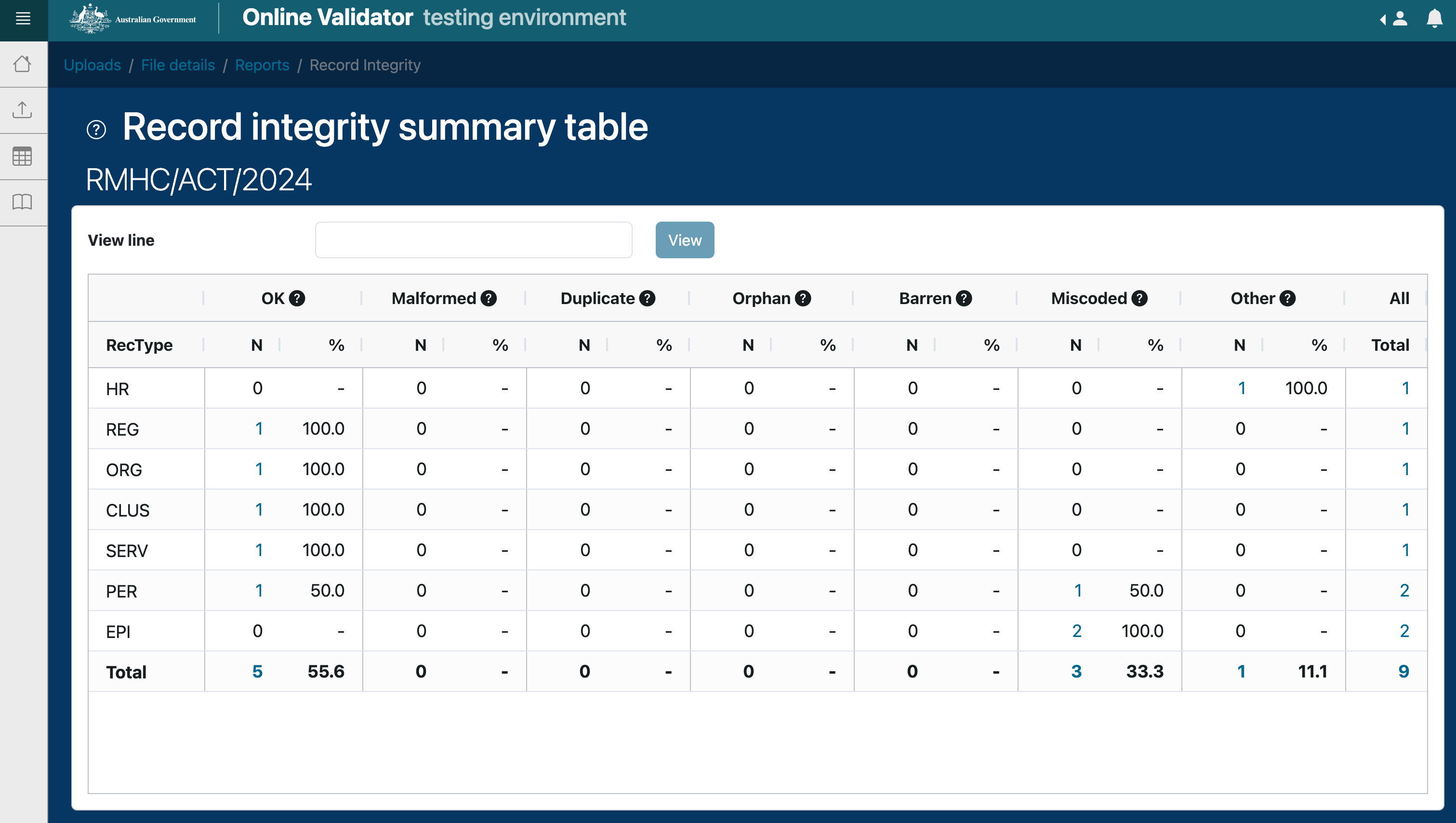
The record integrity report provides a summary of all records, and presents as a tabluar breakdown by record type of detected issues within the file being validated. This report can be used report to identify records that have structural issues, preventing the file from being proposed for review.
Note that it reports in real time so it can be viewed while the validation run is in progress. Doing so can save you from validating an entire file for which it is already evident a rebuild is required.
A count and percentage is displayed for all items flagged as OK, Malformed, Duplicate, Orphan, Barren, Miscoded and Other, along with a total count for each record type and for each flag category.
Record integrity validations ensure:
that records have the correct number of fields, as well as valid data within those fields.
that records specify valid hierarchical entities. For example, an organisation with a region specifies a valid corresponding region record.
that organisations have valid identifiers.
These rules are internal (that is, there is no SQL associated with them) as they are applied while processing the raw uploaded file before the data is extracted into the database.
The record has at least one issue that renders it undecipherable.
Examples include: short lines, bad record types or invalid key fields. The dataset specifications dictate the requirements for each row in detail.
Duplicate
There are two or more records with the same key fields.
Orphan
The record does not have a parent in the submitted file. This can occur if the parent record exists but has irredeemable errors.
Barren
The record is expected to have child records but there are none present. This can occur if the child record exists but has irredeemable errors.
Miscoded
The record has at least one incorrectly supplied non-key field.
Examples include: illegal characters, incorrectly formatted numbers, out of domain values and invalid dates.
Excluded
Applies only to NOCC.
The record has errors which lead to it being excluded from analysis, for example, a Sequence error Incomplete status.
Other
These are non-structural errors that can be investigated further via the Data integrity reports.
Consistency validations ensure that data appears to be reasonable and consistent, both within the current reporting periods and when compared to data submitted in previous reporting periods. Many of these validations have emerged over time in response to errors in past-year data.
The Data integrity reports report on data that is invalid or appears to contain anomalies, for example:
a male client should not have a female-only diagnosis
services should serve a reasonable number of clients
contact durations should be of reasonable length
There are a number of common terms used in the reports, they include;
Record type: Fields under this heading will change depending on the file type being reported. Information on a file’s expected record types is available in the metadata.
Rule: Rules are validations that have been created with the aim of improving data accuracy.
Issue: Highlights uploaded data that triggers a ‘Rule’ that requires further attention.
Each submitted file is evaluated against a set of rules. These rules are generated from both the dataset specifications, as well as rules identified by the Commonwealth and jurisdictions to draw focus to common unusual trends that have been found over the history of the project.
Some rules use Virtual Elements (VFields). These are fields that have not been directly supplied in the data; instead they are calculated from a variety of fields in the submitted data file. VFields and their SQL can be found via the metadata site.
The ‘Download Invalid Records’ link generates a CSV download of all of the invalid records in the datafile. Each row represents a single error; records with multiple errors are repeated with one row per error. This enables users to filter the download as required.
Fig. 6.3 Example export of Invalid HR Level Records report
This report allows users to select data elements, such as the number of clients and the number of contacts, for comparison between submissions.
For example, when comparing the number of clients and contacts between MHE and CMHC, the output provides the difference in clients and contacts between each group both as a number and a percentage. Totals are also provided.
When uploading a new file (MHE/CMHC/RMHC), users have the option to validate the file against that year’s accepted SKL submission. If any entities in the newly uploaded file do not match what is in the SKL file, the Non-matching entities report will helps to identify the unmatched entities.
The Non-matching entities report displays the entities that cannot be matched and lists them in either the Not in SKL column or the In SKL Only column, along with the corresponding rule. Clicking on an entity’s name takes the user directly to the related issue.
This report shows the amount of overlap between the patient identifiers in the NOCC and the CMHC, and NOCC and the RMHC. It has been designed to assist jurisdictions in understanding the integrity of these identifiers for the purposes of subsequent linkage when reporting coverage estimates as is the case with Mental Health Services Performance Indicator (MHS PI) 14, Outcomes readiness.
The NOCC and CMHC/RMHC Total columns indicate the total number of unique person identifiers found in the respective file for the given entity (i.e., at a jurisdiction, region and organisational level).
The Shared Total column indicates the number of unique identifiers found in both files. The NOCC and CMHC Shared columns indicate the percentage of their dataset’s identifiers that were shared with the other dataset.
There are several important considerations when interpreting this report:
The meaning of this report depends on the consistency of region and organisational code sets. This consistency should be assessed initially via validation of the NOCC & CMHC submissions with the MHE Skeleton. If different code sets are used between these collections, there can be no matches with the patient identifiers.
Linkage between the NOCC and CMHC is reported only with those NOCC patient identifiers used for NOCC Collection Occasions in NOCC Ambulatory Mental Health Services Settings and those CMHC patient identifiers where the CMHC person identifier flag indicates a “genuine” unique individual.
The report is generated at the time of initial file validation and compares the current submission of the NOCC/CMHC with the available CMHC/NOCC submission for the given reporting period. With the NOCC data it should be noted that there are additional validation processes applied after acceptance that filter only those data that meet the requirements of the NOCC “business rules” (i.e., one episode at a time, change of setting triggers a new NOCC episode of mental health care).
By way of guidance, we can reasonably expect that “all” consumers recorded on the NOCC in ambulatory settings will have service contacts recording on the CMHC. While there are some differences between jurisdictions, previously we have found that approximately 90-95% of NOCC patient identifiers exist in the corresponding CMHC for that reporting period.
On the other hand, the proportion of CMHC patient identifiers that have NOCC clinical ratings is likely to be in the range 35-40%. This is not surprising given that we have consistently found that approximately 30% of all unique CMHC patient identifiers, in a given reporting period, have service contacts recorded on only one or two service contact days.
It may be useful to generate these reports with previous submissions of the NOCC and CMHC/RMHC to check whether there are in fact new issues being identified in the current submission process (e.g., there may be “known” issues regarding “low” completion rates of NOCC measures by some organisations reporting CMHC service activity).
This CMHC- and RMHC-specific report provides breakdowns of client and activity data, comparing the current and previous year’s CMHC/RMHC data.
Client reports present contact and client counts broken down by client demographic information (age, sex, etc.).
Activity reports present contact, client, contact hours and treatment days broken down by registration status (is the client registered on the system or is the person generated by the presence of a contact).
This report allows users to select and compare information in recently submitted files with that in files that had been submitted previously. Output provided includes current and previous figures and their difference, along with a percentage figure to represent growth for directly apportioned and indirectly apportioned expenditure. Totals are also provided.
The colour coding of the Protocol Adherence Report is as follows:
Green - close to 100% conformance on a mandatory measure.
Yellow - some conformance, but many items missing from a mandatory measure.
Red - low or no conformance on a mandatory measure.
Blue - measures received when no reporting requirements apply. These measures will not be included in the standard NOCC reporting, but may be used by the Jurisdiction for its own reporting purposes.
Adherence to NOCC reporting requirements in current submission is compared with historical trend data to determine whether the current submission is credible and valid.
The colour coding of the Measure Trend Report is as follows:
Green - close to 100% conformance on a mandatory measure.
Yellow - some conformance, but many items missing from a mandatory measure.
Red - low or no conformance on a mandatory measure.
Blue - measures received when no reporting requirements apply. These measures will not be included in the standard NOCC reporting, but may be used by the Jurisdiction for its own reporting purposes.
Person at organisation, cluster and service unit levels
The person identifiers are defined at ORG level but are reported below SERV on PER records. This leads to various complications. Inconsistent values at a PER level is caught by the Differs rules, but it’s still possible to have one valid value and some number of Missing values (or all Missing). Counted differently at different SERV and ORG entity levels:
Same person (orgid+persid) in two units of the same org
Same person (orgid+persid) in two units of the same org on same day
Both could be counted as 2 at reports below ORG and 1 above.
Variable person attributes
The general principle is to use the most recent valid value. In situations where multiple values can be taken by a person, either different values on PER records in different SERVs or over time on CON attributes, then the most recent (ContDt) valid value should be consistently used in all reports. “Valid” depends on the particular variable, but generally just means non-missing and mappable.
Variable person DxPrinc same-day
Find most-recent contact diagnosis prefix for each person. In the case of a multiple, last-day CONs, the RecordId is taken as a stable, albeit arbitrary, tie-breaker.
Country of birth priority
CoB codes in priority order:
Valid: 0001,1000,1100-9999(not 1603)
Not Stated: 0003
Inadequately Described: 0000
Other: ‘ ‘ or out of valid 1603,0002,0004-0999,1001-1099
These priority classes are used by the most recent, valid value rule. Some are more valid than others.
Date of birth priority
More accurate values of DoBFlag are preferred (if present).
Person age
This is calculated at the RepEnd reporting period end date and used in AgeGroup reports.
Treatment day calculation
“Treatment Days” are calculated separately at SERV, CLUS and ORG levels with the result that one ORG person seeing two units on the same day will count as 2 at the lower level and 1 at the higher level.